
亚细胞定位预测与验证结果不一致的原因是什么?
为啥软件预测的亚细胞定位,跟我实验做出来不一样?
做蛋白亚细胞定位,几乎人人都踩过这个坑:先用网站在线预测,显示明明在细胞核、线粒体或者细胞膜,结果自己辛辛苦苦做 GFP 融合表达、做免疫荧光,一拍照完全不是那么回事。位置对不上、弥散在胞质、跑到别的细胞器里,甚至整细胞乱亮。很多人第一反应是:我实验做错了?载体没构建对?转染没转好?其实真不一定是你的问题,预测和验证不一致,是非常普遍、非常正常的事。今天我用最口语、最接地气的方式,把所有真实原因一次性讲清楚,让你一看就明白问题出在哪。
首先你要记住一句话:预测是 “按规矩猜”,验证是 “真实情况”。预测软件只看一条氨基酸序列,它看不到细胞里的真实环境,看不到修饰、看不到互作、看不到动态变化。它就像只看身份证地址判断你住哪,但你实际可能上班、出差、搬家,根本不在那。所以对不上,才更接近真相。
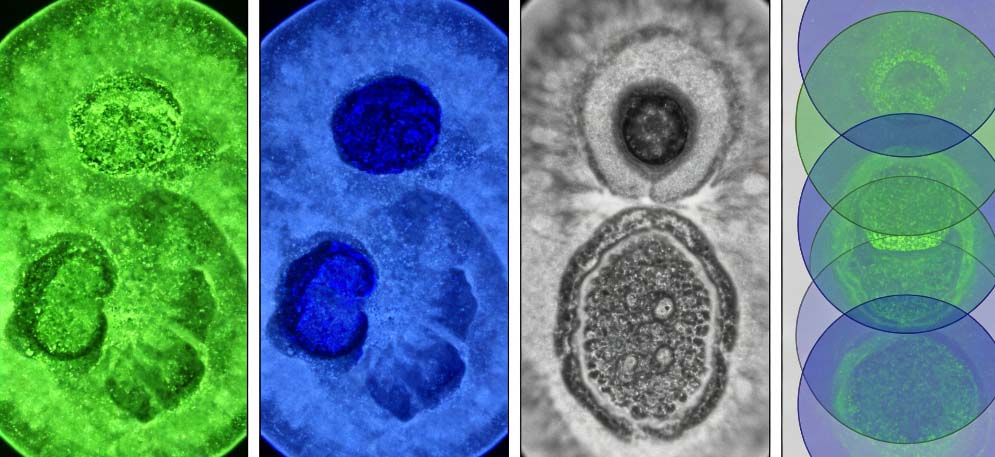
第1个最常见原因:蛋白有不同剪接体,你预测用的和你表达的根本不是同一个蛋白。很多基因不是只表达一种蛋白,而是通过可变剪接,切出长短不一样、结构不一样的亚型。有的剪接体带核定位信号 NLS,有的不带;有的有信号肽,有的被切掉了。软件默认用参考序列,也就是最长的那条来预测,而你克隆、表达的可能是短亚型、截短型,定位信号直接丢了。结果软件说进核,你做出来在胞质,不是错了,是东西不一样。
第2个原因:蛋白会 “搬家”,预测是死的,细胞是活的。绝大多数蛋白不是一辈子待在一个地方,而是受刺激、受调控来回跑。比如很多转录因子,没激素、没逆境、没诱导的时候,老老实实待在细胞质里;一旦受到诱导,立刻进核发挥功能。预测软件不知道你细胞有没有处理,直接按 “静息状态” 给结果,你没加诱导就观察,当然对不上。还有的蛋白在细胞膜工作,损伤应激时跑到线粒体;有的在胞质,分裂期进核。这些动态变化,软件完全预测不出来。
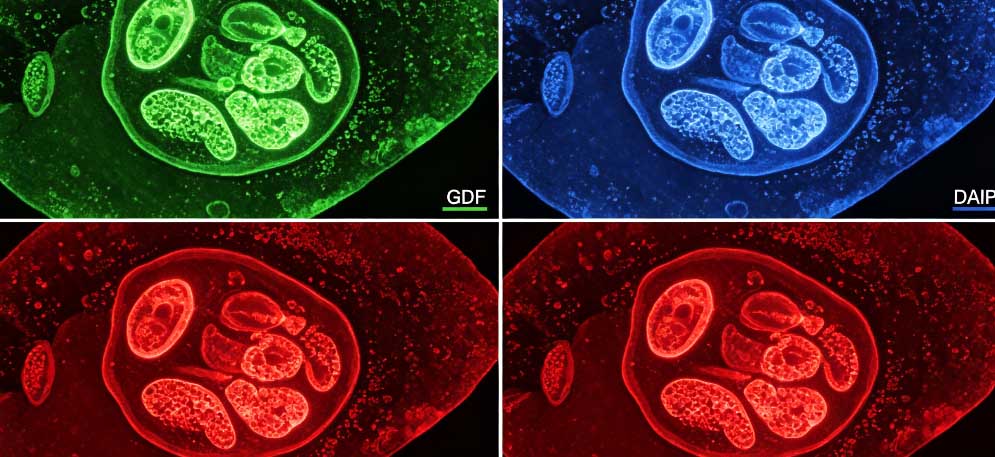
第3个原因:定位信号被折叠 “包里面” 了,外面看不见。软件看序列,看到有 NLS、线粒体靶向序列,就判定能进去。但蛋白合成后不是一根直线,而是会折叠成三维结构。本来在序列里露在外面的信号肽,折叠后可能被包在蛋白内部,转运机器根本识别不到。就像你口袋里有钥匙,但被衣服裹得死死的,掏不出来,门还是开不了。这种情况软件认为能定位,实际根本进不去,只能留在原地。
第4个原因:你的标签影响了蛋白定位,这是最容易被忽略的。做亚细胞定位,几乎都要带 GFP、YFP、Flag、Myc 这些标签。但标签不是随便加的。如果标签加在 C 端,而定位信号正好也在 C 端,直接被挡住;如果标签太大,会改变蛋白结构、影响折叠;甚至有些标签本身就有弱定位倾向。本来蛋白能正常定位,一带标签就跑偏、滞留、弥散。尤其是膜蛋白、核蛋白、小肽,对标签位置特别敏感,一挂错就全错。
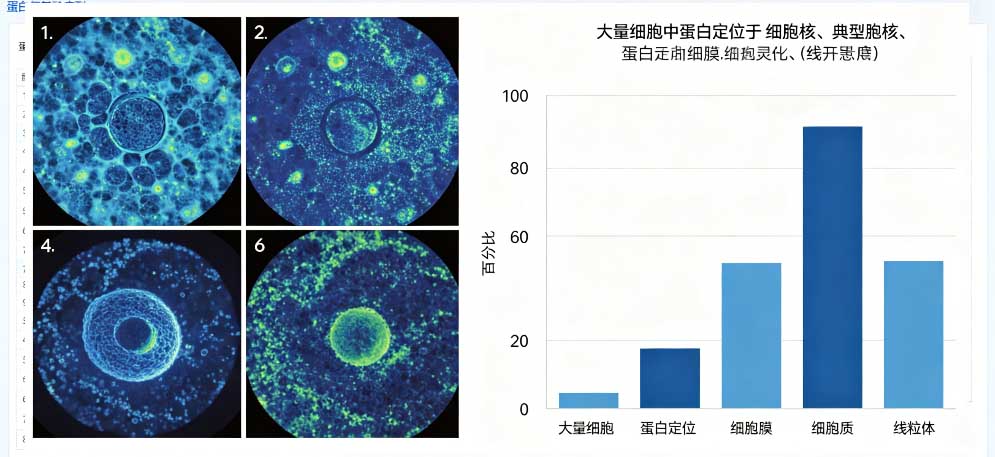
第5个原因:过量表达把系统 “撑爆了”,蛋白被迫待错地方。我们在细胞里过表达蛋白,表达量通常比天然状态高几十倍、上百倍。细胞里负责转运的蛋白、通道、载体数量是有限的,一下子涌进来太多蛋白,转运系统忙不过来,多余的蛋白只能滞留在细胞质、内质网,或者随便堆在某个地方。本来精准定位的蛋白,一过量就变成全细胞弥散,你一看和预测不一样,其实是表达量太高导致的人工假象。
第6个原因:实验固定、透膜、染色操作导致蛋白移位、泄露。尤其是免疫荧光,步骤非常影响结果。固定时间太长、透膜过度,细胞膜、核膜被破坏,蛋白会跑出来;固定不够,蛋白会弥散、漂移。有些蛋白本来在膜上,透膜一处理直接跑到胞质;核蛋白固定不好会散得到处都是。这些都是操作带来的 “假定位”,不是蛋白真实位置,自然和预测不一致。
第7个原因:蛋白本来就不止一个定位,软件只给一个答案。很多蛋白是 “双定位” 甚至 “多定位” 的,既在细胞核又在细胞质,既在线粒体又在过氧化物酶体,或者在细胞质和细胞膜之间循环。预测软件只会输出概率最高、最常见的一个位置,不会告诉你它还有第二个家。你实验看到两个位置,就以为对不上,其实是软件没把完整信息告诉你。
第8个原因:跨物种表达,细胞不认识这个蛋白的 “地址码”。比如你把植物蛋白放到动物细胞里表达,把动物蛋白放到酵母里表达,不同物种的定位信号、转运系统、识别机制不一样。你的蛋白带着原物种的 “地址”,但新宿主细胞看不懂,不知道往哪运,最后只能随便滞留。软件按原物种预测,你在异源细胞验证,肯定对不上。
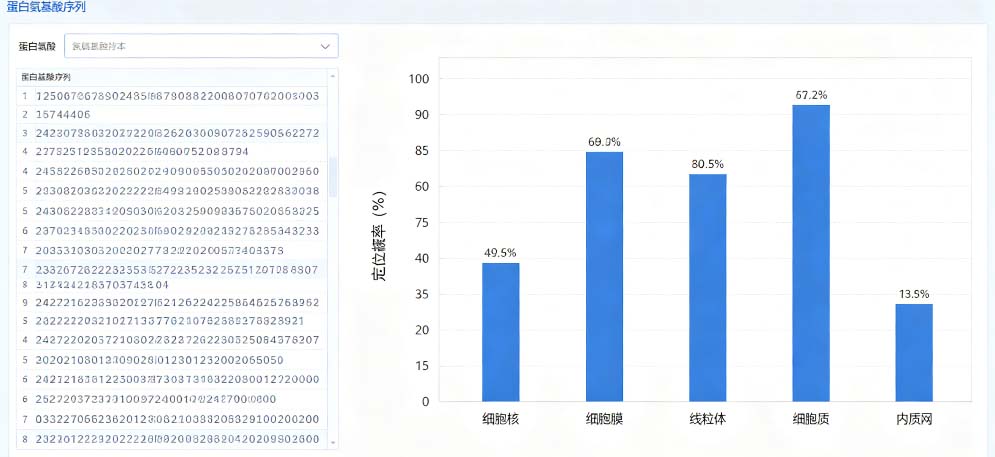
第9个原因:蛋白会被修饰,一修饰位置就变。磷酸化、乙酰化、泛素化、糖基化,都会直接改变蛋白定位。比如磷酸化之后,核蛋白被挡在核外;去磷酸化才能进核。软件只看裸序列,完全看不到修饰,而你细胞里的蛋白是被修饰过的天然状态,基础条件都不一样,结果自然不一致。
第10个原因:预测数据库本身就不全,算法很粗糙。现在的预测工具,对人、小鼠、拟南芥这些模式物种还准一点,对非模式生物、冷门物种、新蛋白,数据非常少。很多新发现的定位信号、非常规转运方式,数据库还没更新,软件根本识别不出来。它只能靠有限的特征硬猜,猜错是常态,猜对才是运气。
亚细胞定位预测,永远只能当参考,不能当结论。实验验证才是金标准。出现不一致,先不要怀疑自己,先排查这几件事:是不是剪接体不同?有没有加诱导处理?标签位置对不对?表达量是不是太高?操作有没有造成弥散?是不是跨物种表达?
很多时候,预测和验证对不上,不是失败,反而是好消息。因为这说明你的蛋白存在动态转运、修饰调控、条件依赖、双定位这些重要机制。很多好文章、好发现,就是从 “预测不准” 里挖出来的。所以放平心态,不一致才是细胞的真实样子,只要你实验重复稳定、结果可靠,那就相信你的实验,不用被软件带着走。
最新动态
-
06.18
亚细胞定位预测与验证结果不一致的原因是什么?
-
06.18
无需抗体、跨物种通用:三篇高水平论文实证DAP-seq如何助力植物转录调控?
-
06.11
打破“单向用药”的局限!IF=11.9《Asian J Pharm Sci》证实:红参外泌体,口服就能双向调控骨代谢
-
06.11
植物外泌体研究前沿:2026年4—5月6项突破性成果系统梳理
-
06.11
IF 26.8!颠覆“越小越好”的认知:南方医科大团队用40微米的柠檬胶囊,让肠屏障主动“开门”抗癌
-
06.11
从零开始研究一个基因,这篇讲透了!
-
06.11
解码RNA互作奥秘:金开瑞RIP/RNA pull-down试剂盒助力多篇高质量研究,深入解析肿瘤及椎间盘退变调控机制
-
06.11
别再大海捞针了!虚拟筛选正在改变药物发现的方式!
-
06.11
BiFC还是LCA?你的蛋白互作该用哪种荧光互补技术?
-
06.11
荧光素酶5大高分案例+实验小技巧!
 X
X 






