
别再大海捞针了!虚拟筛选正在改变药物发现的方式!
在药物研发领域,有一个广为人知的困境:筛选出一个有潜力的先导化合物,往往需要测试成千上万甚至数十万个分子。这个过程不仅耗时漫长、成本高昂,而且失败率极高。
传统的实验筛选方式,常被比喻为“大海捞针”。
但近年来,随着计算生物学的发展,一种更高效、更精准的手段正在改变这一局面——虚拟筛选。它不再依赖盲目的实验试错,而是通过计算机模拟,在分子层面快速预测蛋白质与化合物之间的结合能力,从而大幅缩小实验验证的范围。
一、什么是虚拟筛选?
虚拟筛选是一种基于计算方法的药物发现技术。它通过分子对接算法,模拟药物分子(配体)与靶点蛋白(受体)之间的相互作用,预测两者是否能够稳定结合,并估算结合强度。
目前最主流的分子对接引擎之一是 AutoDock Vina。它在标准测试集上的结合能预测与实验值的误差约为2–3 kcal/mol,排序准确度约70–80%,被广泛应用于学术研究和工业筛选。
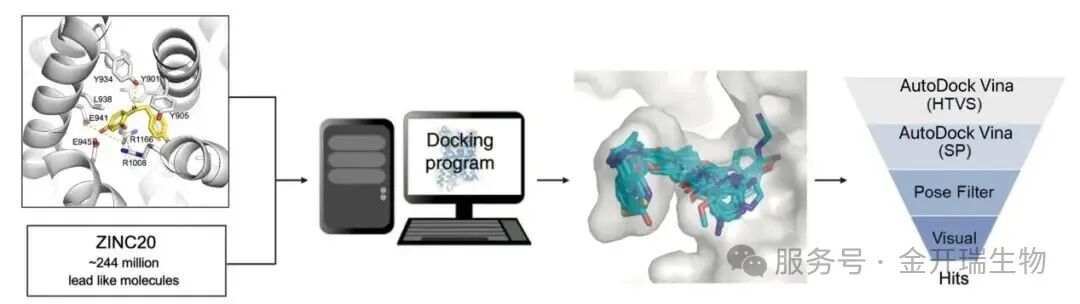
二、一个标准的虚拟筛选流程是怎样的?
一套成熟的虚拟筛选流程,通常不是“一次性”对接就结束,而是采用分级筛选策略,在速度和精度之间取得平衡。
01、化合物预处理
在对接开始之前,需要将原始的化合物文件转化为计算机可计算的格式。常用工具 OpenBabel 完成以下操作:
➤2D→3D结构转换
➤加氢
➤Gasteiger电荷计算
➤能量最小化(MMFF94力场)
最终生成 PDBQT 格式文件,这是 AutoDock Vina 对接的标准输入。
02、高通量粗筛
对大规模化合物库进行快速对接,保留结合亲和力排名 Top 5% 的候选分子。这一阶段的目的是在百万级分子中实现高效过滤,用尽可能少的计算资源快速缩小候选范围。
03、虚拟精筛
对初筛得到的 Top 5% 分子,提高对接精度(如增加exhaustiveness),再次进行对接,进一步筛选出 Top 5% 进入下一轮。这一阶段聚焦潜在高活性分子,剔除明显假阳性。
04、精细化分析
对精筛后的候选分子,通过 MODEL 和 Log 文件深入解读结合模式,分析关键氢键、疏水作用和 π-π 堆积等相互作用,锁定最优先导化合物。
这种分级筛选策略的核心逻辑是:在前期用速度换取广度,在后期用精度换取深度。既不遗漏潜在分子,也不在无意义的候选上浪费计算资源。
三、虚拟筛选能做什么?——经典案例
以一篇近期发表在 Journal of Medicinal Chemistry 上的研究为例(doi:10.1021/acs.jmedchem.5c01483),研究人员面对的是一个非常棘手的靶点——艰难梭菌毒素B(TcdB)。该毒素存在多个亚型,结构复杂,传统抗体药物难以全覆盖。
他们采用多级虚拟筛选策略:
➤对超过10,000个FDA批准药物进行对接,覆盖8种TcdB亚型和2个关键结合界面,总计超过16万次模拟;
➤对Top分子进行MM/GBSA自由能计算和分子动力学模拟,排除假阳性;
➤成功筛选出先导化合物 Dirlotapide,后续细胞实验和动物模型验证了其中和活性。
这说明:一套设计合理的虚拟筛选流程,能够从海量分子中精准锁定真正的“潜力股”。
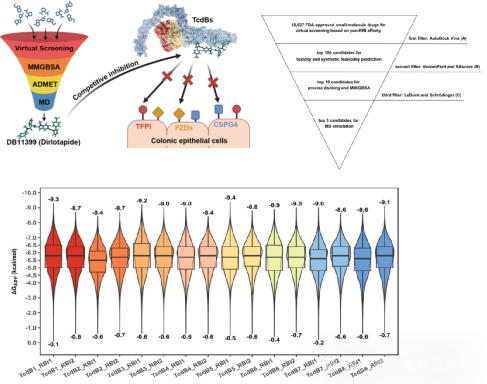
多级虚拟筛选策略及其对TcdB受体结合界面的结合亲和力分析
四、虚拟筛选的应用场景
虚拟筛选并不是只适用于某一种研究,它的适配范围非常广:
➤药物早期先导化合物发现:针对靶点蛋白快速筛选化合物库,大幅降低实验成本;
➤老药新用/药物重定位:预测已上市药物与新靶点的结合能力,拓展适应症;
➤农药研发:筛选针对植物病原菌、害虫关键蛋白的活性化合物;
➤化学生物学研究:解析小分子与蛋白的相互作用机制;
➤天然产物活性挖掘:从天然产物库中快速筛选有潜力的分子。
五、虚拟筛选的核心优势
与传统实验筛选相比,虚拟筛选在以下几个方面具有明显优势:
|
维度 |
传统实验筛选 |
虚拟筛选 |
|
周期 |
通常数月甚至更长 |
缩短为1-2周 |
|
成本 |
高(耗材、人力) |
低(主要算力投入) |
|
通量 |
百级到千级 |
万级到百万级 |
|
数据可追溯性 |
较差 |
强(结合能、构象、相互作用均可记录) |
|
假阳性控制 |
依赖经验 |
可通过多级筛选控制 |
注意: 虚拟筛选不是万能钥匙
无法预测化合物的代谢稳定性、毒性、溶解度等ADME性质
对蛋白柔性强的靶点(如GPCR)预测精度有限
结果依赖输入结构质量(PDB或AlphaFold模型)
六、哪些项目适合做虚拟筛选?
如果你正在面临以下情况,虚拟筛选可能是一个高效的选择:
✅ 有靶点PDB但不知道筛什么化合物
✅ 有化合物库但不想盲目实验
✅ 想发文章补充计算验证
✅ 想做老药新用但缺乏计算资源
七、关于我们的虚拟筛选服务
我们专注于基于 AutoDock Vina 引擎的有机小分子虚拟筛选,面向科研机构和制药企业提供高通量蛋白质-小分子对接分析。
核心能力:
高效稳定:自主研发的批量对接脚本,支持同时处理数千个配体,计算周期短
专业精准:优化对接参数,结合能预测重复性好,满足科研发表要求
分层筛选:采用粗筛→精筛→结果评估的分级策略,有效控制假阳性率
完整交付:提供结合能排名表、Top化合物对接构象及分析报告
服务流程:
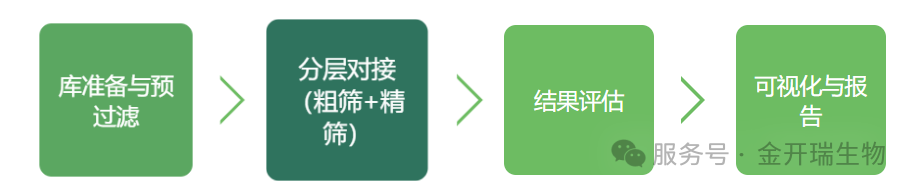
服务周期参考:
单蛋白 vs 100–1000个配体:5–7个工作日
虚拟筛选不是“魔法”,它不能保证每一次筛选都直接得到候选药物。但它确实为药物发现提供了一条更理性、更高效、更低成本的路径。
最新动态
-
07.08
葡萄外泌体“激活细胞清道夫”——SM@G-ELNs协同水凝胶通过MERTK介导的巨噬细胞胞葬作用促进糖尿病伤口愈合(IF=14.3)
-
07.08
三篇顶刊论文,同一个技术选择——BiFC如何破解植物蛋白互作难题?
-
06.24
再登《Cancer Research》!金开瑞双荧光素酶报告系统助力机制研究新突破
-
06.24
登上《Gut》(IF 26.8)!南方医科大学团队揭示葛根类外泌体纳米囊泡靶向肠道细菌治疗类风湿关节炎新机制
-
06.18
亚细胞定位预测与验证结果不一致的原因是什么?
-
06.18
无需抗体、跨物种通用:三篇高水平论文实证DAP-seq如何助力植物转录调控?
-
06.11
打破“单向用药”的局限!IF=11.9《Asian J Pharm Sci》证实:红参外泌体,口服就能双向调控骨代谢
-
06.11
植物外泌体研究前沿:2026年4—5月6项突破性成果系统梳理
-
06.11
IF 26.8!颠覆“越小越好”的认知:南方医科大团队用40微米的柠檬胶囊,让肠屏障主动“开门”抗癌
-
06.11
从零开始研究一个基因,这篇讲透了!
 X
X 






